Brett Rosolen, AARNet’s eResearch Data Program Manager talked about the Big Data Flow problem at QUESTnet2016 and explained how Science DMZ can help. Here are the key points from his presentation:
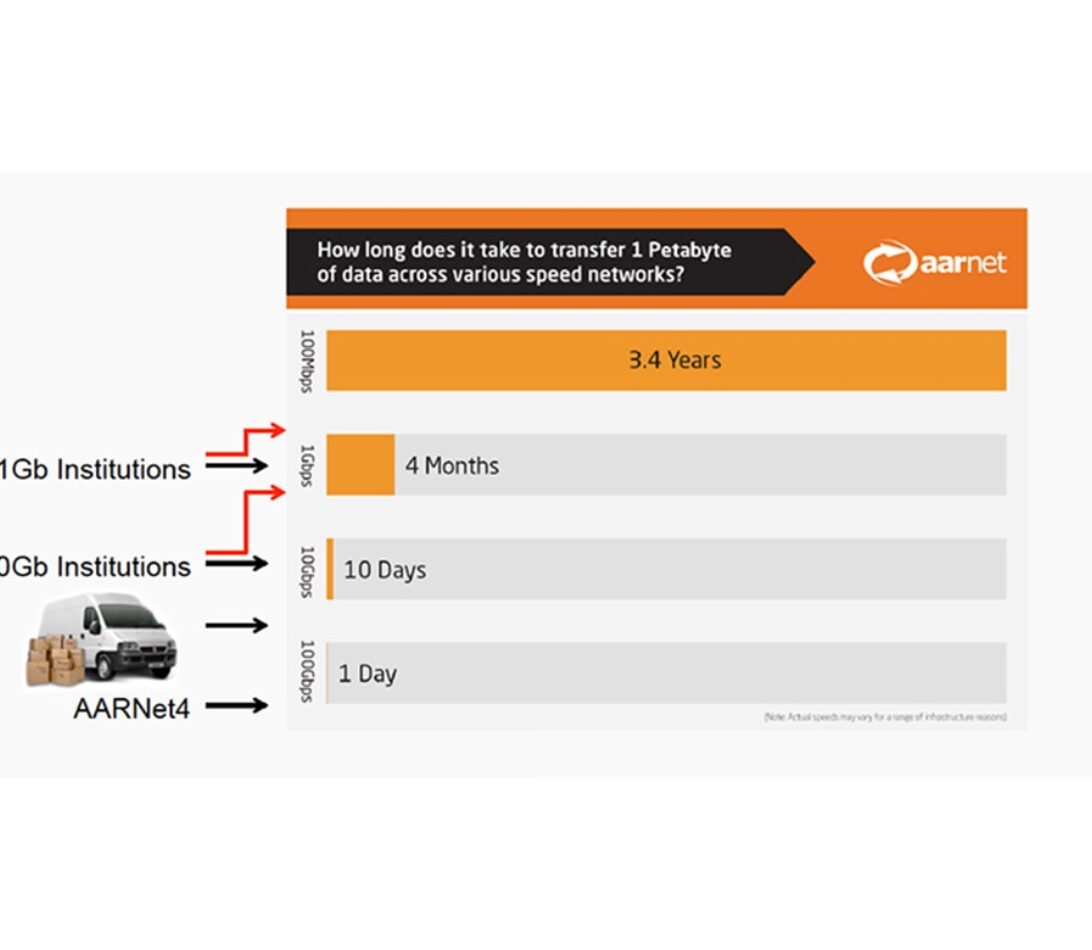
To address the increasing demand for moving large datasets it seems only natural that we just need to build more bandwidth, right? After all, it’s often been said that “Big Data needs Big Networks”. Ok! So let’s just build multiple 100Gbps circuits both nationally and internationally and surely our research community can now simply move a full Petabyte in a single day? Happy days … or is it? Apparently not!
So, what’s the problem?
As a nation, we have made a significant collective investment in our shared research infrastructure over many years. To take advantage of this investment requires a great network that has been built for freely moving data to where it is most useful. However, our research community’s ability to scale up workflows to take full advantage of order of magnitude changes in network capacity is lagging well behind.
The campus network architecture is not designed for large science data flows
Security at the campus edge is designed to cater for thousands of small flows rather than a few very big ones, end-to-end visibility of network capacity is poor for most users, and transfer tools typically used are simply incapable of leveraging the capacity when network latency heads north. It’s really no wonder that our research community generally has expectations well below what is achievable for moving big datasets, with some even resorting to sneakernet (moving data storage physically) as the default workflow.
AARNet4 has the potential to move a Terabyte of data in 20mins
For example, an institution with a 10Gigabit per second (Gbps) connection to the AARNet network could potentially transfer 1 Terabyte of data in about 20 minutes. However, using a campus network configuration built to cater for the entire enterprise, rather than large research data flows, and with tools and systems not equipped to cater for transfer over a WAN, the likely reality is that a single data transfer is would be limited to closer to 1-2Gbps, and will subsequently take 2-3 hours… that’s almost an order of magnitude difference, or 10x slower.
and a Petabyte of data in a day
With very large datasets we can see (view infographic at top of post) that AARNet4 can cater for moving a Petabyte in a day. However with the campus network constraining large data flows so significantly the time taken to move that Petabyte becomes completely impractical. In fact, so much so that sneakernet actually becomes a much more attractive option. The result is a complete failure to leverage the power and value of the network that has been “purpose built for research”!!
Our aim
Our aim is to help change all that and increase the expectations of researchers from every institution for moving large volumes of data. We need to ensure that our community understands how AARNet4 and a Science DMZ approach can have a profound impact on the research community’s ability to move and access their data.
What exactly is this ‘Science DMZ’ and how will it help?
The Science DMZ concept was created by the Energy Sciences Network (ESNet) in the US. It is defined as a portion of the network, built at or near the campus or laboratory’s local network perimeter that is designed such that the equipment, configuration, and security policies are optimized for high-performance scientific applications rather than for general-purpose business systems or “enterprise” computing.
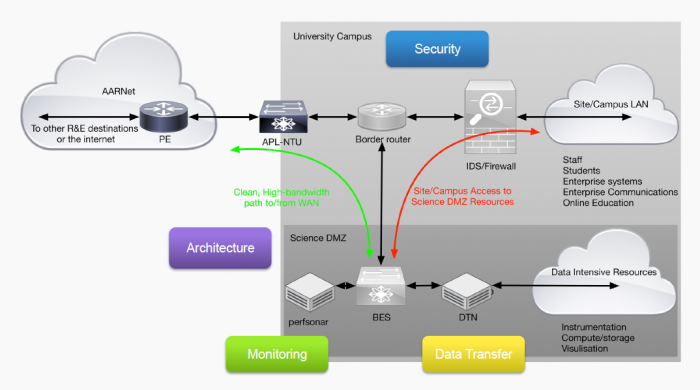
A Science DMZ integrates four key concepts into a unified whole that together serve as a foundation for this model:
Architecture – manage ‘science’ network independently. This separates the data-intensive resources from the main campus network, allows more appropriate security methods to be applied for large flows, and accommodates a range of scalable connectivity options, including redundancy, virtual private networks and additional wavelengths.
Security – tailored for a few large science flows. Typical firewalls support many small flows rather than few large ones- the small buffers lead to significant packet loss, and subsequently very poor performance. As most large transfers are between few resources, use router access control lists instead of very expensive large buffer firewalls. Separating elephant flow security from campus security is a relatively inexpensive win-win for both science and campus.
Monitoring – characterize and set network performance. perfSONAR Nodes allow proactive monitoring of critical science pathway and set expectations for end to end network performance. perfSONAR uses a dedicated mesh of tools spread across the national research network, with a dashboard for overall visibility, and creates an active deployed fault-finding mesh to assist rapid targeting for network errors.
Data Transfer – dedicated tuned systems and tools. Use Data Transfer Nodes, or simply DTNs for access to local storage via either direct high-speed disk, a SAN or mounted high-performance parallel filesystem (e.g. Lustre or GPFS). These DTNs have tuned high-speed network interfaces, matched to the WAN bandwidth, and a collection of proven transfer tools which can sustain high data transfer rates over long latencies, e.g Aspera, Globus. DTNs do no general purpose computing tasks to mitigate security risks.
Example: How Science DMZ works for a dependent simple network
Has Science DMZ made a difference?
Internationally, the ESNet approach to answering the Big Data Flow problem has refined the architecture, with significant resources for all aspects of addressing the data movement problem made available at http://fasterdata.es.net
In Australia, we have demonstrated significant performance improvement to line rate utilisation through the robust deployment of DaShNet (RDSI) and national infrastructure. Bottlenecks are now *not* at Science DMZ capable end points, but often “the other end” or further up the stack, which highlights that both sender and receiver capabilities are both critical to improving Big Data flows.
Introducing our data transfer benchmarking service
The impact has been so significant that we have permanently built a data transfer benchmarking service on AARNet4 for institutions to test to from their campus network and/or data intensive science resources. This service is available now for testing all AARNet connected institutions.
Is Science DMZ good for my university?
The answer is going to have a “yes” in it somewhere, with benefits for both for research outcomes AND the enterprise! In order to determine the nature of those benefits, it’s important to assess both the current capabilities of the network for data throughput and in parallel the current and expected demand for large data access by the institution’s research community.
What’s the plan?
We are recommending that every institution takes the first two following steps.
Step 1. Diligence on benchmarking – how fast can you go? In a coordinated manner with us test from your border / faculty against our benchmarking capability. You can use our portable 10G Data Transfer Nodes, deploy test perfSONAR nodes on known transfers routes and conduct user machine / instrument throughput tests from deep within your campus architecture.
Step 2 – Diligence on demand – where’s your data? This involves assessing your research community for the potential for improvement by capturing transfer tools in use, assessing NetFlow data, or simply “asking around” research groups for indicative or expected performance.
These two steps should identify performance across borders or known choke points, provide greater visibility on current and anticipated larger flows in/across/out of campus, and better insight into discipline-specific choice and capability of tools. This all adds up to and proactive engagement with research and a demonstrated commitment to improve access to data.
Once the above is done, a qualified approach to any follow-up implementation can be made.
Step 3 – Science DMZ implementation – demonstrable follow through in support of research. We can work with you to identify Science DMZ architecture and/or components to address issues discovered. Then, you build and operate, or we build, you operate, or AARNet Enterprise Services can build and operate (Science DMZ as a Service).
To leverage our collective investment in national and institutional research resources we are proposing the Australian research community takes a collective approach to ensure that large flows are catered for between all sites. This requires a community effort (AARNet, universities, research institutions, scientific instruments, high-performance computing facilities and other resources supporting research) to collectively accommodate the delivery of large datasets, leading to the more efficient and secure delivery of data-driven research outcomes.
We use cookies to improve your experience on our site. While you browse, you agree to our use of cookies. If you'd like to learn more about how we use them, you can read our privacy policy.